GitHub - tenaan/AI-study: 💻 AI study 정리
💻 AI study 정리. Contribute to tenaan/AI-study development by creating an account on GitHub.
github.com
4장 핵심 내용 정리
Keywords | 손실 함수, 경사하강법, BGD, SGD, MGD, Bias-Variance Tradeoff
이번 글에서는 4.4 학습 곡선 절까지 정리한다.
이번 장에서는 모델을 훈련시키는 방법으로 손실 함수의 개념과 이 손실 함수를 최소화하기 위한 대표적인 기법으로 경사하강법에 대해서 소개한다.
데이터에 적합한 복잡도의 모델을 찾는 관점에서 손실 함수(오차)를 활용할 수 있음을 보이며, 이 손실 함수의 변화를 관찰함으로써 과대적합 Overfitting, 과소적합 Underfitting을 판단하고자 한다.
선형 회귀 Linear Regression
일반적으로 선형 모델의 식은 특징 feature에 대한 가중치 합 weighted sum과 편향 bias로 이루어진다.
y^ = (θ₁x₁ + θ₂x₂ + ... + θₙxₙ) + b
- y^: 예측값 (prediction)
- x₁, x₂, ..., xₙ: 각 특징(feature)들
- θ₁, θ₂, ..., θₙ: 각 특징에 대한 가중치(weight) (모델 파라미터 Model Parameter)
- b: 편향(bias) (= θ_0*x_0, x_0은 항상 1)
평균 제곱근 오차 RMSE / 평균 제곱 오차 MSE
회귀에서 가장 널리 사용되는 성능 측정 지표는 Root Mean Squared Error (RMSE)로 실제로는 Mean Squared Error (MSE)를 최소화하는 theta를 찾아서 선형 회귀 모델을 훈련시킬 수 있다.
어떤 함수를 최소화하는 것은 그 함수의 제곱근을 최소화하는 것과 같으므로 보통은 계산적으로 더 간단한 MSE를 최소화하는 방식으로 훈련하게 된다.
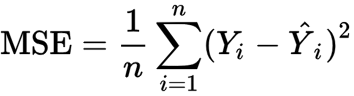
언제 MSE, MAE, RMSE를 사용하는가?
제목에 열거한 RMSE, MSE, MAE는 딥러닝 모델을 최적화 하는 데 가장 인기있게 사용되는 오차 함수들이다. 이번 포스팅에서는 (1) 이들의 특징을 알아보고, (2) 이 3 가지 손실 함수를 비교 분석해본다
jysden.medium.com
이번 장에는 나오지 않았지만 MAE에 대한 설명과 이상치를 얼마나 반영하냐에 대한 관점에서 이 글도 읽어보면 좋을 것 같다. 이상치가 많고 이에 대한 영향을 덜 받고 싶을땐 MAE를 사용하는 것이 좋다. MSE와 RMSE의 차이에 대해서도 더 자세하게 설명되어 있다.
또한 추가적으로 적을 수 있는 내용으로는, 모델을 훈련시킬 때 사용하는 평가 기준인 손실 함수과 훈련이 끝난 모델의 최종 성능을 평가하는 평가 기준은 서로 다를 수 있다.
성능 평가 지표는 재현율, 정밀도와 같은 미분 불가능한 기준일 수 있고, 학습 시의 손실 함수는 미분 가능하고 효율적인 기준을 선택하게 된다.
좋은 손실 함수는 최적화하기도 좋으면서, 해당 값을 줄이면 최종 성능 평가 지표도 덩달아 좋아지게 한다.
분류 모델을 훈련시킬 때는 보통 컴퓨터가 최적화하기 쉬운 로그 손실을 사용한다. 이 로그 손실 값을 최소화하도록 모델을 학습시키면, 우리가 최종적으로 원하는 목표인 정밀도와 재현율도 결과적으로 향상되는 경향이 있기 때문이다.
이 손실 함수를 최소화하기 위한 두 가지 방법을 소개한다. 해석적인 방법으로 최소가 되는 theta를 한 번에 구할 수 있는 정규 방정식과 반복적인 연산을 통해 점진적으로 최소가 되는 theta를 찾는 경사하강법이 있다. 정규 방정식은 자주 쓰이지 않기 때문에 간단하게 정리하고 넘어가겠다.
정규 방정식 Normal Equation
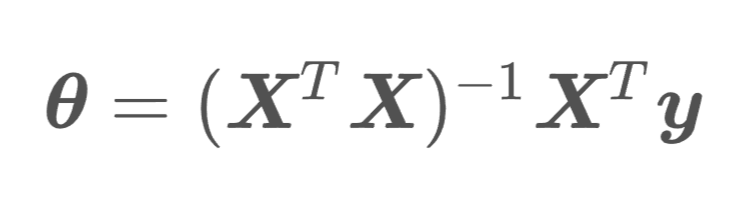
손실 함수를 최소화하는 theta를 찾는 정규 방정식은 위와 같은 식으로 나타낼 수 있다.
실제 구현에서는 위와 같은 식으로 계산하지 않고 언제나 역행렬을 구할 수 있어 안정성이 높은 유사역행렬(Moore–Penrose inverse)을 사용하게 된다. 이 유사역행렬은 특잇값 분해(Singular Value Decomposition, SVD)라는 행렬 분해 기술을 통해 계산된다.
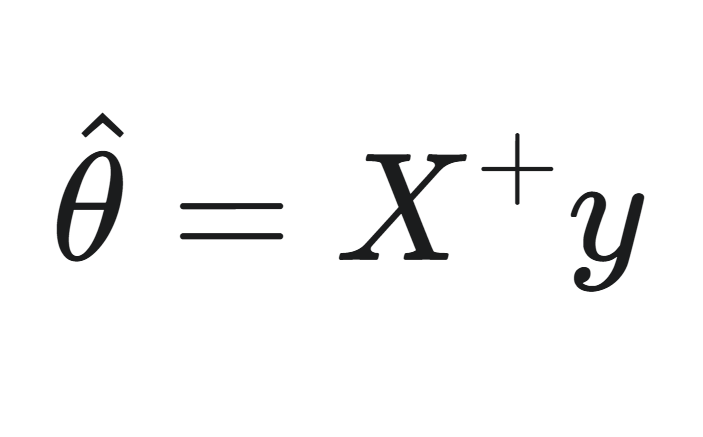
유사역행렬 X^+로 위와 같이 나타낼 수 있다.
코드 상에서도 np.linalg.pinv() 를 사용해서 직접 계산할 수 있다.
np.linalg.pinv(X_b) @ ySVD는 행렬을 직교 행렬, 대각 행렬, 그리고 또 다른 직교 행렬의 곱으로 분해하는 방법이다.
https://m.blog.naver.com/combioai/220861349129
특이값분해(singular variable decomposition, SVD)와 의사역행렬(pseudo inverse matrix)
회귀분석(regression analysis)을 할 때 통계적인 기법들을 적용해서 하는 방법외에, 선형대수학을 이용해...
blog.naver.com
SVD와 유사역행렬에 대한 자세한 과정은 위 블로그를 참고하자...
정규방정식은 (n + 1)× (n + 1) 크기의 X^TX의 역행렬을 계산한다(n은 특징 수). 역행렬을 계산하는 계산 복잡도는 일반적으로 O(n^2.4)에서 O(n^3) 사이로 특징 수가 늘어나면 그만큼 계산 시간도 늘어난다. SVD 방법도 대략 O(n^2)의 복잡도를 가진다. 샘플 수에 대해서는 선형적으로 증가한다.
두 방식 모두 특징 수가 10,000개 이상이 되면 계산 시간이 매우 느리기 때문에 잘 쓰지 않는다.
특징 수가 많거나 샘플이 많아서 메모리에 모두 담을 수 없을 때 쓰기 적합하지 않다.
경사 하강법 Gradient descent
경사 하강법은 일반적인 최적화 알고리즘으로 반복적인 연산을 통해 파라미터를 조정하는 것이다.
현재 파라미터에 대한 손실 함수의 Gradient를 계산해서, Gradient가 감소하는 방향으로 진행한다. 전역 최솟값 Global Minimum에 수렴할 때까지 점진적으로 향상시킨다.
- 학습률 Learning Rate
- 중요한 파라미터로 한 번 감소할 때, 얼마나 감소할 것인지 Step의 크기를 정하는 하이퍼 파라미터이다.
- 학습률이 너무 작으면, 시간이 오래걸리고 너무 크면, 발산할 수 있다.
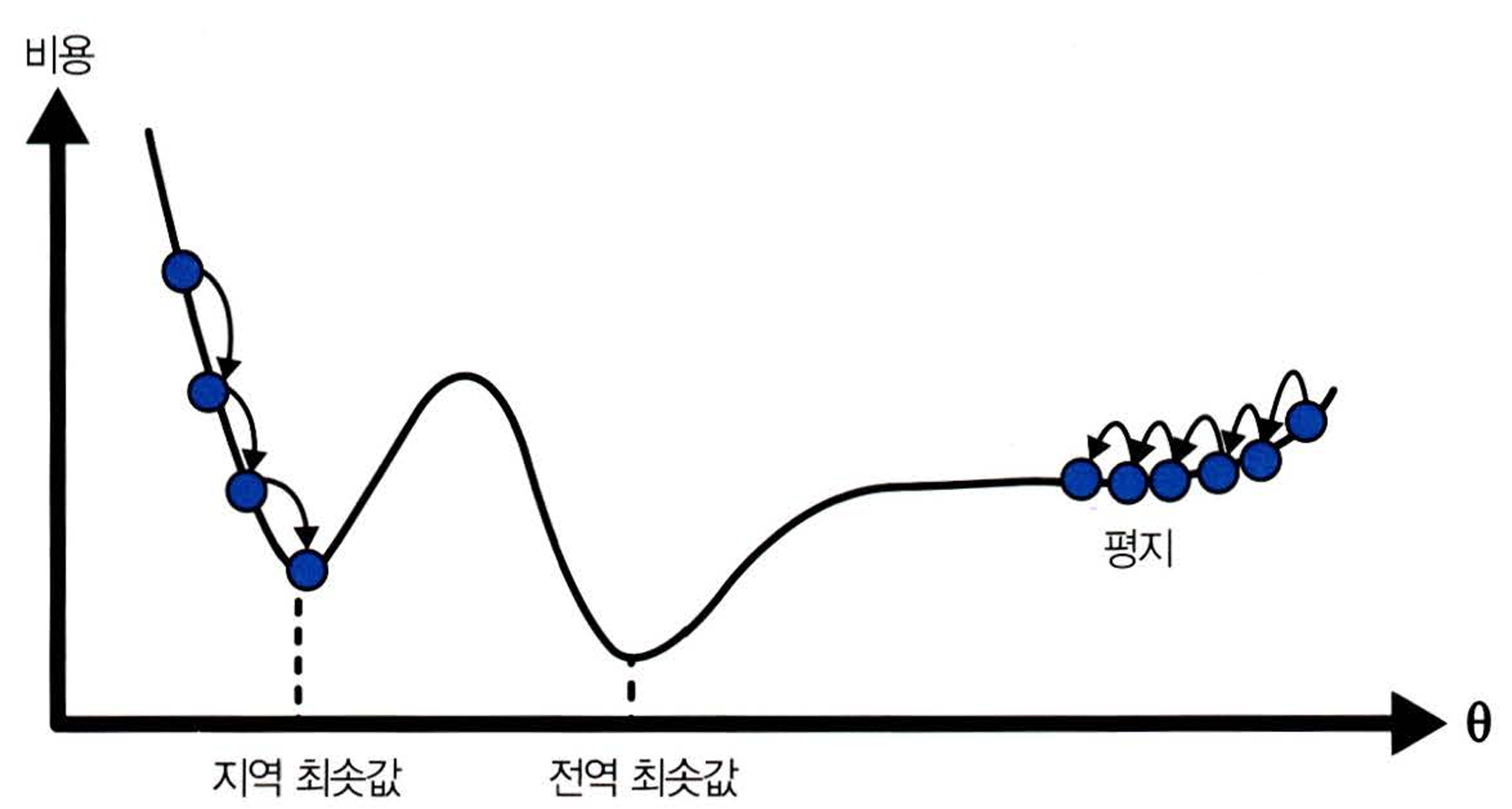
모든 손실 함수가 전역 최솟값에 쉽게 수렴할 수 있지는 않다. 초깃값은 랜덤으로 정해지기 때문에, 시작점이 어디인지에 따라 수렴하는 곳이 달라질 수 있다.
MSE 손실 함수는 Convex Function으로 하나의 전역 최솟값을 가진다.

위 그림의 오른쪽의 경우 특징의 스케일 Scale이 다른 경우로 특징 1, theta 1의 스케일이 더 작은 경우를 보여준다. 특성 1이 더 작기 때문에 비용 함수에 영향을주기 위해서 theta 1이 더 크게 바뀌어야하고 그림과 같이 길쭉한 모양이 된다.
오른쪽의 경우 최솟값에 도달하는 시간이 더 오래걸리게 된다.
따라서 경사 하강법을 사용할 땐, 사이킷런의 StandardScaler 등을 사용하여 모든 특징의 스케일을 같게 만들어야한다.
특징, 즉 파라미터가 많아질 수록 파라미터 공간이 커지고 최솟값을 찾기 어려워진다.
배치 경사 하강법 Batch Gradient Descent Method, BGD
배치 경사 하강법에서는 매 스텝에서 전체 훈련 세트에 대해 계산한다.
각 모델 파라미터에 대한 편도 함수 Partial Derivative를 구해서 파라미터 theta가 변경될 때, 손실 함수가 얼마나 바뀌는지 계산한다.


Gradient Vector를 구하고 그 반대 방향으로 theta에서 학습률 만큼 빼준다.
확률적 경사 하강법 Stochastic Gradient Descent, SGD
이렇게 전체 훈련 세트를 사용할 때의 문제점은 매우 느리다는 것이다.
확률적 경사 하강법은 매 스텝에서 한 개의 샘플을 랜덤으로 선택하고, 하나의 샘플에 대한 Gradient를 계산한다.
랜덤으로 샘플을 선택하므로 훨씬 불안정하고 최솟값에 안착하지 못한다.
하지만 손실 함수가 불규칙할 때, 지역 최솟값을 건너뛰고 전역 최솟값을 찾을 가능성이 높기도 하다.
이에 대한 해결책으로 초기에는 학습률을 크게 해서 지역 최솟값에 빠지지 않도록 하고, 점차 학습률을 줄여서 전역 최솟값에 도달하도록 한다.
학습률을 조절하는 것을 학습 스케쥴 Learning Schedule 이라고 한다.
SGD를 사용할 때, 훈련 샘플이 Independent and Identically Distributed를 만족해야 전역 최솟값을 향한다고 보장할 수 있다. IID는 데이터 포인트들이 서로 독립적이며 동일한 확률 분포를 따른다는 가정이다. 이는 훈련하는 동안 샘플을 섞음으로써 만족할 수 있다.
미니 배치 경사 하강법 Mini Batch Gradient Descen, MGD
앞의 두 기법의 중간점이라고 생각할 수 있다. 미니배치라고 부르는 임의의 작은 샘플 세트를 정하고 Gradient를 계산한다. 행렬 연산에 최적화된 하드웨어인 GPU를 사용해서 성능을 향상시킬 수 있다는 장점이 있다.
미니배치 사이즈를 크게하면 SGD보다 덜 불규칙하지만 지역 최솟값에 빠질 수도 있다.
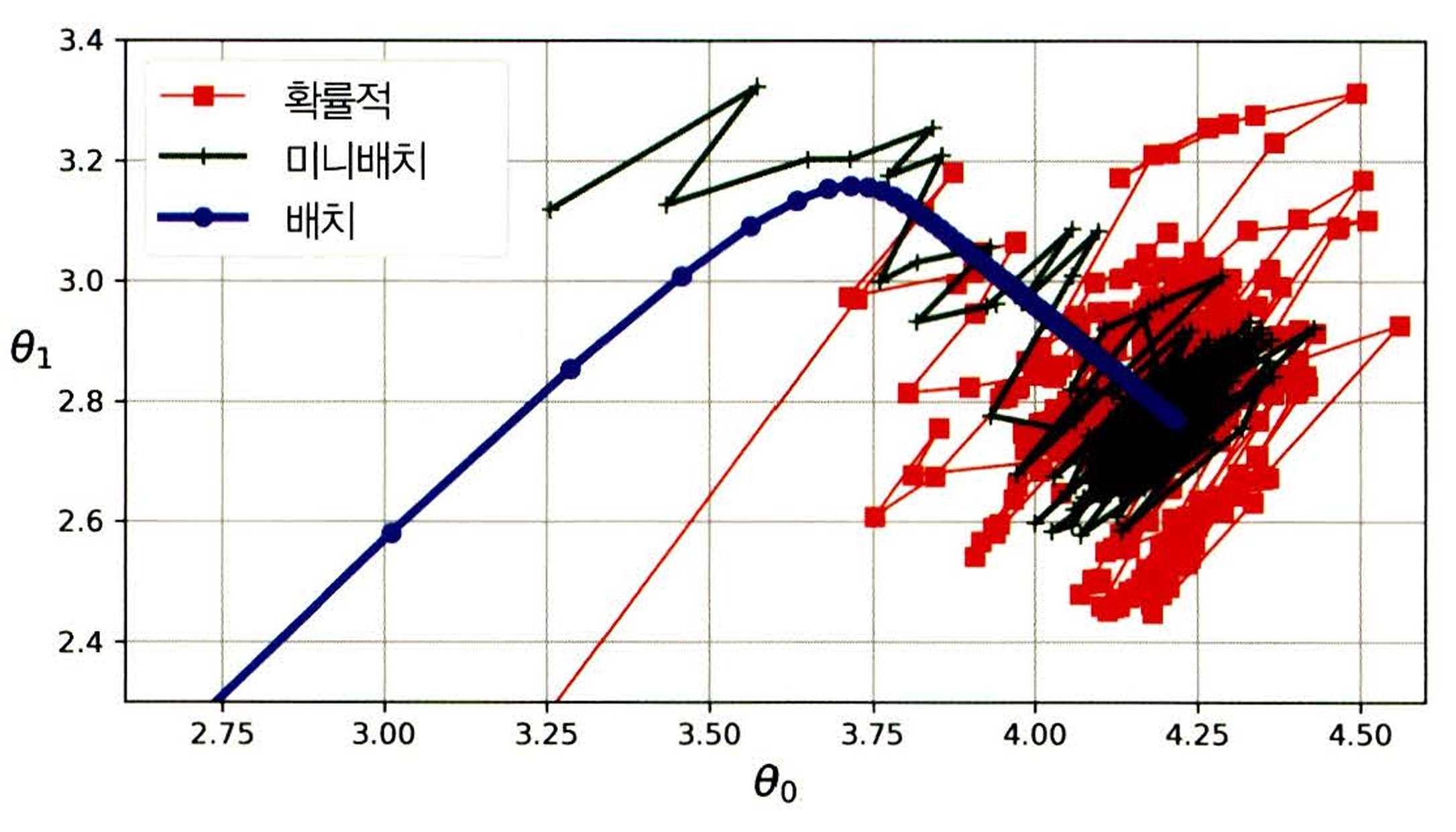
위 그림을 통해 3가지 알고리즘의 경로를 비교해볼 수 있다. BGD는 최솟값에서 멈췄고 SGD, MGD는 최솟값 근처에서 맴돌고 있다. 하지만 SGD와 MGD도 적절한 학습 스케쥴을 사용하면 최솟값에 도달할 수 있다.
다항 회귀 Polynomial Regression
비선형 데이터를 학습할 수 있도록, 각 특징의 거듭제곱, 특징들의 곱으로 상호작용 항 Interaction Term을 새로운 특징으로 사용해 선형 모델을 훈련 시키는 것을 다항 회귀라고 한다.
일반적인 선형 회귀 모델은 찾을 수 없는 특징들 사이에 숨겨진 관계를 찾아낼 수 있다.
학습 곡선

고차원의 다항 회귀는 훨씬 데이터에 과대적합되었고 선형 회귀를 보면 과소적합된 것을 볼 수 있다.
어떠한 훈련 데이터가 주어졌을때, 해당 데이터에 얼마나 복잡한 모델을 사용해야할지, 모델이 과대 혹은 과소적합 되었는지 판단하기 위해서 학습 곡선을 확인할 수 있다.
훈련 세트와 검증 세트에서 일정한 간격으로 모델을 평가하고 (손실 함수) 그 결과를 그래프로 나타낸다.
그래프 예시를 통해 어떻게 판단할 수 있는지 알아보자.
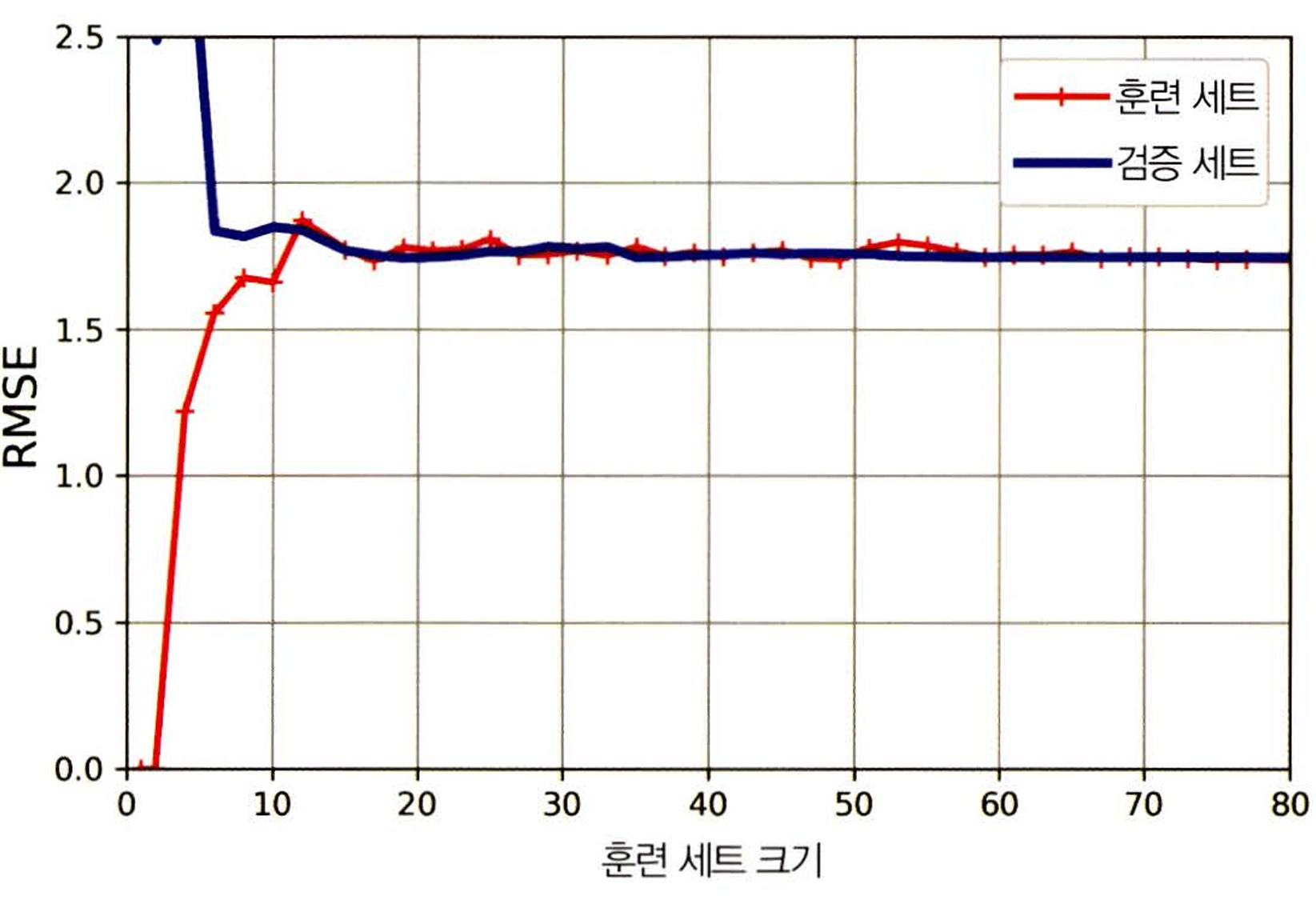
훈련 세트에서의 오차를 먼저 살펴보자. 오차가 계속 상승하다가 샘플이 추가되어도 오차의 변화가 거의 없는 평편한 구간에 도달했다.
검증 세트에서의 오차 또한 감소하다가 평편한 구간에 도달했다.
두 곡선이 수평한 구간을 이루고 높은 오차에서 가까지 근접해있다. 이 경우에는 과소적합 되었다고 볼 수 있다.
이렇게 과소적합된 경우에는, 훈련 샘플을 추가해도 효과가 없으며 더 복잡한 모델을 쓰거나 다른 특징을 선택해야 한다. 위 경우는 비선형 데이터에 선형 모델을 사용한 경우이다.
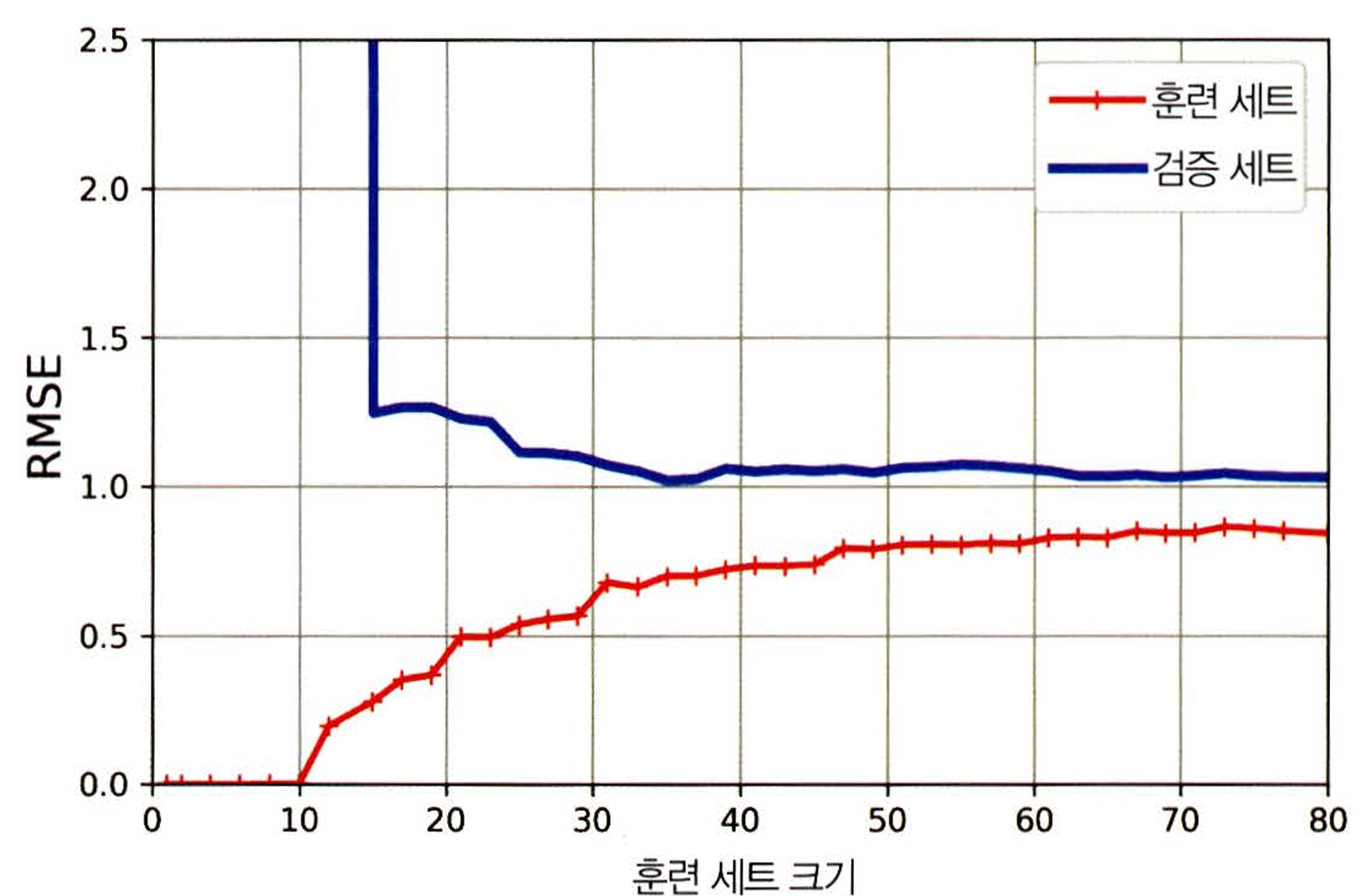
위 그래프에서는 훈련 세트에서의 오차가 이전보다는 낮다. 두 곡선 사이에 공간이 있으며 이 경우에는 훈련 세트에서 더 나은 성능을 보인다는 것이다. 이는 과대적합의 신호로 볼 수 있다.
과대적합된 경우에는 검증 세트에서의 오차가 훈련 세트의 오차에 근접할 때까지 더 많은 훈련 데이터를 추가해서 개선할 수 있다.
편향-분산 트레이드오프 Bias-Variance Tradeoff
오차를 편향, 분산, 그리고 데이터 자체가 내재하고 있어 어떤 모델링으로도 줄일수 없는 오류 Irreducible Error의 합으로 보는 것이다.
- 편향은 잘못된 가정으로 인한 오차이다. 예시로는 2차원의 데이터인데 선형으로 가정하는 경우이다.
- 편향이 큰 모델은 과소적합되기 쉽다.
- 분산은 작은 변동에도 모델이 민감하게 반응하는 것이다. 자유도가 높은 모델은 높은 분산을 가지기 쉽다.
- 분산이 큰 모델은 과대적합되기 쉽다.
- 줄일 수 없는 오류는 데이터 자체에 있는 잡음으로 인해 발생한다. 이상치를 제거하는 것과 같은 데이터의 잡음을 줄임으로써 오차를 줄일 수 있다.
모델의 복잡도가 커지면 분산은 커지고 편향은 작아지지만, 복잡도가 작아지면 분산은 작아지고, 편향은 커지는 Tradeoff 관계이다.